

.jpeg)
IT incident management is a fundamental operational process designed to ensure rapid service restoration. This process is typically assigned to the help desk but is also very much entrenched in the day-to-day of DevOps.
When incident management goes right, service is restored quickly and the impact on productivity, continuity, and customer satisfaction is minimal.
However, when it doesn’t go right, user and organizational performance is impaired, and the damage can be measured by financial loss, increased costs, and a decrease in customer loyalty and brand equity.
Needless to say, a high performing incident management process is a strategic mandate for every organization, regardless of size, shape, location, or industry.
Incident management vs. incident response
To get incident management right, it is important to first understand the full cycle of what this entails and how it is different from incident response.
Incident response involves technical activities for the analysis, detection, defense, and containment of an incident, whether IT related, cyber related, or any other disruption to the operation and delivery of the organization’s IT services.
Incident management, however, is much broader than that. It is an end-to-end process that involves a greater scope of logistics, communications, planning, aligning, and reporting across a many more domains and stakeholders both within and outside the organization.
Simply put, incident resolution is just one aspect of incident management – granted, a very important aspect, but just one.
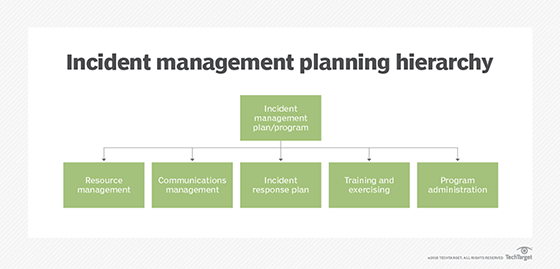
Why you should build your own incident management process
Since no two businesses are the same and since the composition of roles and skills of both IT operations and DevOps teams can vary greatly, copy-pasting a templated approach to incident management will rarely result in optimal results.
This is why for IT ops and DevOps, the incident management process guidelines that are provided by the ITIL (the Information Technology Infrastructure Library, which offers detailed practices for IT service management, including incident management) are just that – guidelines.
And that’s just the starting point.
The 9 step incident management process
For any organization to tailor an incident management process to its unique DNA, mode of working, and aggregated skill sets, it is important to first outline the basic components of that process.
1: Incident logging
Once an incident has been identified it is logged as a ticket by the service desk. This ticket includes information such as the user’s name and contact information, a description of the incident, and date and time of the initial log.
2: Incident categorization
This step is part of the logging process and involves assigning a category and typically at least one subcategory to the incident.
The benefits of doing so includes enabling incident handlers to sort and model incidents as based on their own categories and subcategories vs. generic ones, as well as for automated prioritization, when needed and if possible.
3: Incident prioritization
This is another part of incident logging and represents an important enabler of SLA adherence.
Namely, when priority is determined in accordance with the potential impact on users and the business, as well as urgency, it is much easier to understand how quickly the resolution must be achieved and to measure the scope of anticipated damage if the SLA isn’t met.
4: Incident assignment
This step involves the first responder or incident management lead determining which technician or other stakeholder is best suited to handle particular aspects of the incident and assigning them to handle the task/s.
5: Task creation and management
When the incident requires the involvement and handling of multiple stakeholders from various departments, management is typically broken down to tasks that are executed by individuals who possess the required know-how.
6: SLA management and escalation
SLA management primarily involves the technician, incident coordinator, or incident lead ensuring that SLAs aren’t breached, i.e. that the response is being achieved in accordance with pre-defined requirements.
If the stakeholder assigned to resolve the incident is unable to provide a resolution or sees that those assigned to tasks are not meeting SLAs, the Incident is then escalated to the requisite level of support.
7: Incident resolution
This is the stage that follows the implementation of a solution to service disruption and involves solution testing to verify service recovery.
8: Incident closure
Once it has been confirmed that the Incident has been resolved to the satisfaction of all stakeholders, including users, customers, and management, the Incident is closed.
9: Incident review & remediation
After the incident is closed, the incident lead or coordinator will then need to ensure that the initial classification details and all other documented steps and reports are accurate and accessible for future reference, learning, and optimization.
How to build your own incident management process
Once you have the basics down, building an effective incident management process that is tailored to your organization’s needs means also implementing the following best practices.
Set defined roles and responsibilities
Setting well defined roles and responsibilities is critical to effective incident management.
The roles that typically comprise the incident management team include:
- Incident manager: holding the primary responsibility for driving and optimizing the incident management process.
- First line support: the single point of contact for end users.
- Level two support: those with more advanced knowledge who often take on tasks that the first line support folks can’t.
- Communication lead: keeps the incident team, users, customers, and management updated as the incident and its resolution unfold.
- Tech lead: possesses the requisite technical knowledge and helps to drive the technical resolution.
Establish communication guidelines
To make sure that everyone knows how to communicate with each other – times, channels, and tone of voice, guidelines should be set.
For example, who is most easily reachable via email, text, or Slack; which time zone limitation must be adhered to (or not); and where team updates should be taking place, e.g. Zoom, Slack, or a virtual situation room.
Prepare templates and tools
One of the key enablers for shortening the learning curve and driving overall efficiency is to create templates.
Many incidents tend to recur. And when you have a template model for a password reset, for example, support staff can complete the task much faster and with greater efficacy.
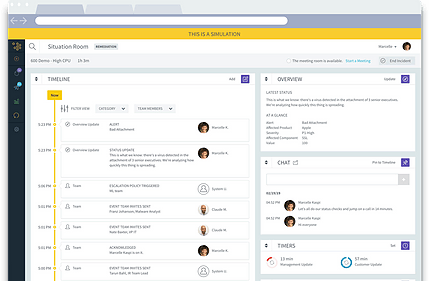
The other side of the template coin is tools, i.e. the ones that are needed for carrying out incident management tasks quickly and effectively.
One such tool is the “known error database” (KEDB), which is maintained by problem management, and is designed to identify problems or known errors that have caused incidents in the past.
KEDB also provides information about workarounds that have been identified and which can greatly benefit the current situation.
Another tool is the incident model which streamlines processes and reduces risk by defining the steps to be taken to handle the incident, their sequence, what are the roles and responsibilities that are involved, which precautions should be taken, what are the timelines required, and how to escalate procedures, among others.
Refine categorization and prioritization
Since every incident presents multiple opportunities for learning how to do things better, faster, smarter – it is critical to continuously go back to your category definitions and prioritization to refine them as based on lessons learned.
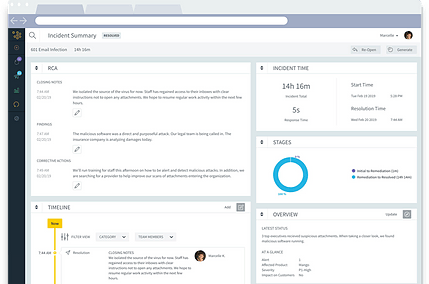
Create insightful incident post-mortem reports
When creating your post-incident post-mortem report, it is critical to go beyond just the what, when, and how much.
To make these reports insightful and ensure that they serve as the go-to source for process optimization it is important to include timelines, sufficient background, a detailed plan to rectify outstanding action items, and to do so in a way that is blameless – focusing on the process rather than the people.
In a world where incidents happen all the time, and where the optimal approach to managing them is one that is tailored to your organization’s DNA, know-how, and operational culture, nothing can serve you better than the ability to build your own incident management process.
To do so, it is critical to first identify the ‘anatomy’ of the process, and then to implement tried-and-true best practices, as outline in this article.
To learn how Exigence can help you optimize incident management with automated orchestration, a unique virtual situation room, and streamlined visibility and management through a single pane of glass, we invite you to reach out to us at info@exigence.io.




