

.jpeg)
If you strip the buzzwords and TLAs from the definition of DevOps? You’ll find that the roles and tasks involved aim mostly for more uptime and less downtime in the SDLC (software development lifecycle). The first step to achieving that is becoming aware of downtime as it happens with the help of monitoring solutions. Only then can you respond and resolve the issue in a timely manner that minimizes the dreaded and expensive downtime of software development teams.
The high cost of downtime
The importance of ensuring uptime cannot be understated. This is because when DevOps teams are slow to resolve a critical incident? The costs are high – very high.
The average cost per ticket in North America is $15.56. This cost increases as the ticket gets escalated, with an L3 ticket coming at approximately $80-$100 and more. In a survey conducted by ITIC, 33% of respondents noted that the cost of one hour of downtime can reach $1 million, and sometimes even up to $5 million.
Data center outages are costly as well. Every minute in the data recovery journey can cost from $137 to $427. The average hourly cost of an infrastructure failure is estimated at $100K, and the average cost of a critical application failure is between $500K to $1M per hour.
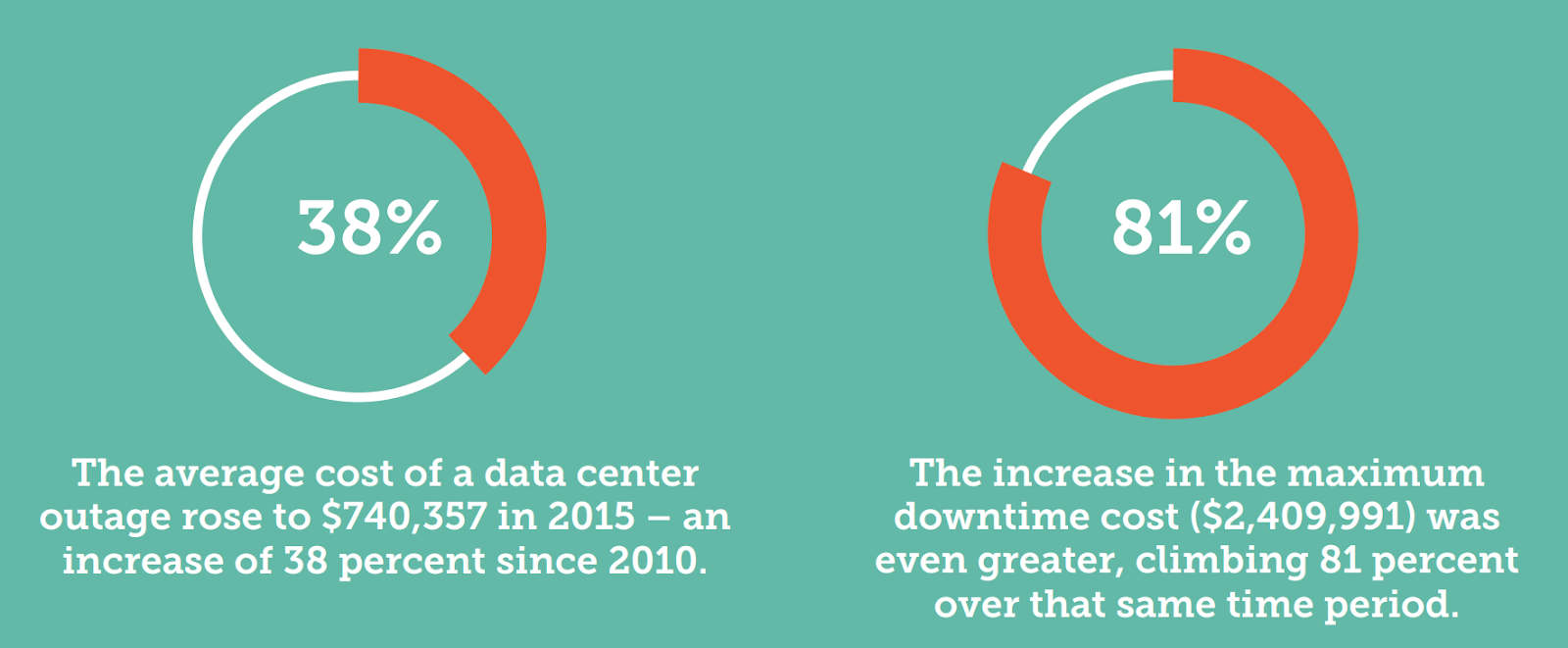
It’s clear that when time costs that much money? You need to respond at lightning speed. Which means you need to be aware of any outage or downtime in real or near-real-time. This is where monitoring and observability come into play.
Let’s take a look at each, how they are different from each other, and why every DevOps team needs both in their incident management and resolution arsenal.
What is monitoring in DevOps?
Monitoring systems enable DevOps engineers to view and understand the state of a system using a predefined set of metrics and logs. By monitoring the behavior of various components in a system, DevOps engineers can be first on the scene to detect failures when they occur.
Moreover, monitoring plays a vital role in enabling the analysis of long-term trends, dashboard design, and alerting.
Monitoring in DevOps supports three main incident management goals:
- Issue detection
of incidents such as outages, service degradations, bugs, and unauthorized activity; alerting to such issues when they arise and presenting relevant data via dashboards.
- Issue resolution by answering the question “what” and “where,” and delivering information that supports troubleshooting and root cause analysis.
- Continuous improvement of the software delivery process by providing insights that support enhanced capacity and financial planning, trending, performance engineering, and reporting.
Ultimately, monitoring in the DevOps CI-CD pipeline drives the collection of the data required to support automated problem detection and alerting, manual debugging when necessary, and overall system health analysis – each of which is critical to accelerated incident resolution.
What is observability in DevOps?
If monitoring is a tree in DevOps incident resolution? Then observability is the forest. That is, if monitoring lets you know when and where something has gone wrong, observability helps you see the bigger picture (i.e. the forest for the trees), by answering ‘why did it go wrong?’.
Having observability means being able to extract actionable insights from the monitoring tool logs. With these insights, you can have a fuller picture of the health and performance of your systems, applications, and infrastructure.
The primary components of observability are:
- Logging for keeping a record of incidents so that teams can learn from previous events to accelerate finding the source and reason for an error. This plays a critical role in debugging.
- Tracing, which is regarded by some as the most important part of observability, as it enables the understanding of the relationship between the cause and effect of an issue. Traces are often visualized through a waterfall graph, enabling developers to understand the time taken in a system, across queues, network hops, and servers. Ultimately, it makes the observable system more effective and drives root cause identification.
- Metrics are the quantitative data that is collected, and enables developers to spot trends that emerge over days, weeks, and months.
Among the key benefits of observability is in the process of transforming masses of data into insights that are actionable and accessible to anyone. Without the proper tools, you find yourself with more and more devices monitored, and a growing mass of logs that are created every second. In such a case data can be more of a bane than a benefit.
Employing observability provides access to knowledge on how to solve anomalies. The more data that is collected and analyzed, the higher the likelihood that this data can be leveraged to accelerate incident resolution. It may even help in pre-empting issues before they arise.
Observability vs monitoring: what is the difference?
Monitoring is a subset of observability. Only a system that is observable can be monitored. Monitoring tools track the overall health of an application, aggregate data on how it’s performing, and when something goes wrong, alert you to what is happening and where.
Observability, on the other hand, is not something that you do. Rather, observability is something that you have. As opposed to monitoring, observability is proactive, leveraging the logs of monitoring together with machine learning and causation to deliver visibility and understanding of not only what is happening and where, but why and how to fix it.
In addition, it’s important to note that ‘observability’ is not just a fancy word for monitoring. It is the whole that is greater than the sum of its monitoring (and other) parts.

To know that something has gone wrong is important – and that’s what we have monitoring for. But, when it comes down to it, knowing when something has gone wrong is simply not enough in today’s software development world.
What DevOps teams need are insights – better, wider, more accurate. The kind that are only possible with observability.
By knowing the difference between monitoring and observability and the goal of each, the symbiotic relationship between the two can be leveraged for powerful incident resolution acceleration.
To learn how Exigence can also help you take your incident resolution even further, we invite you to reach out to us at info@exigence.io.




